Introducing Cogito v2.1
Takeaways
- We are releasing the best open-weight LLM by a US company: Cogito v2.1 671B
- On most industry benchmarks and our internal evals, the model performs competitively to frontier closed and open models, while being ahead of any other US open model.
- We also built an interface where you can try the model: chat.deepcogito.com. This is free and we don't store any chats.
- This model uses significantly fewer tokens amongst any similar capability models, because it has better reasoning capabilities. It also has improvements across instruction following, coding, longer queries, multi-turn and creativity.
Release Details
The model weights1 are available on Huggingface.
The model is also available as an API on OpenRouter, Fireworks AI, Together AI, Ollama's cloud, Baseten, and RunPod. You can also run the model locally using Ollama or Unsloth .
Evaluation
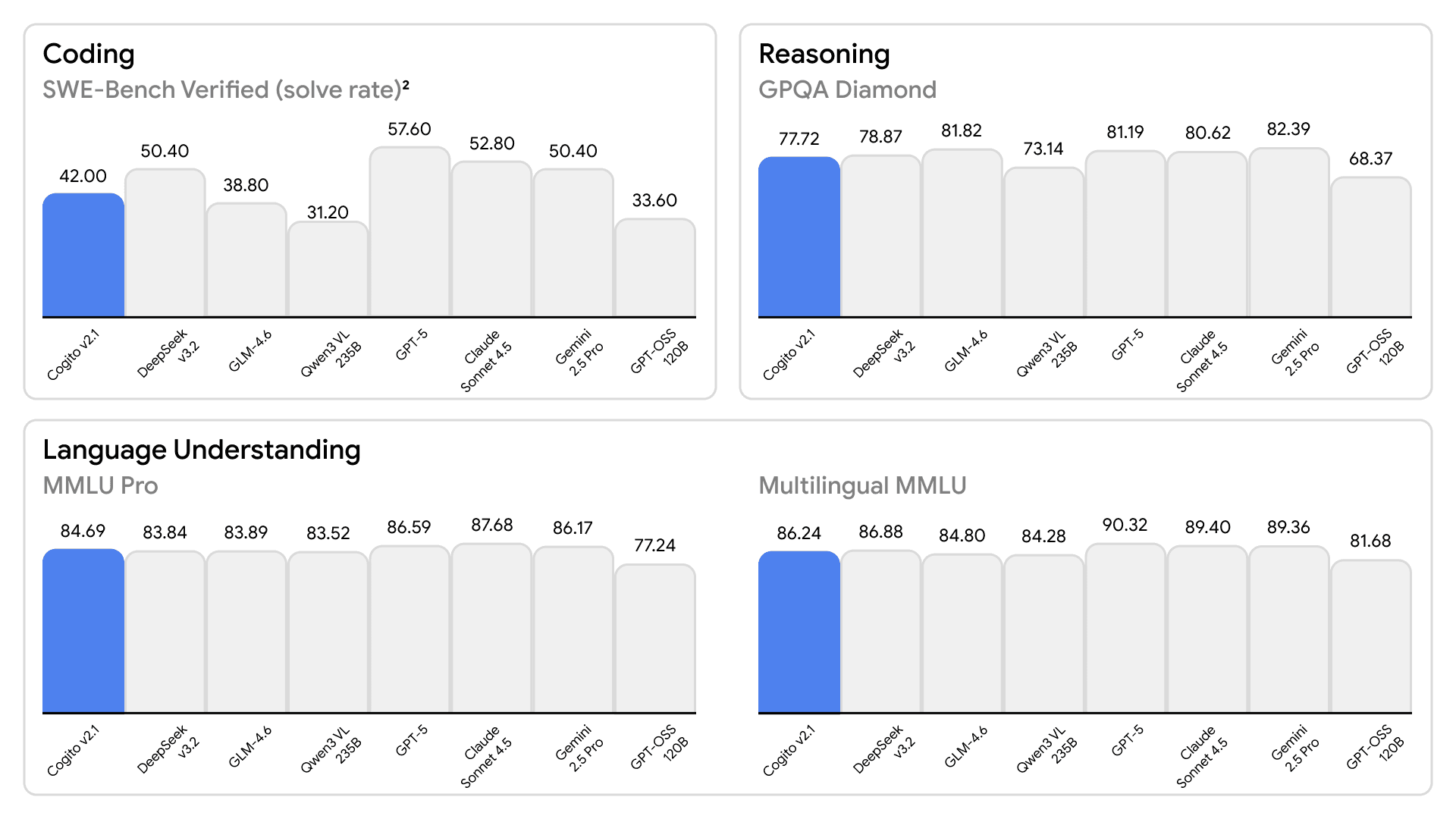
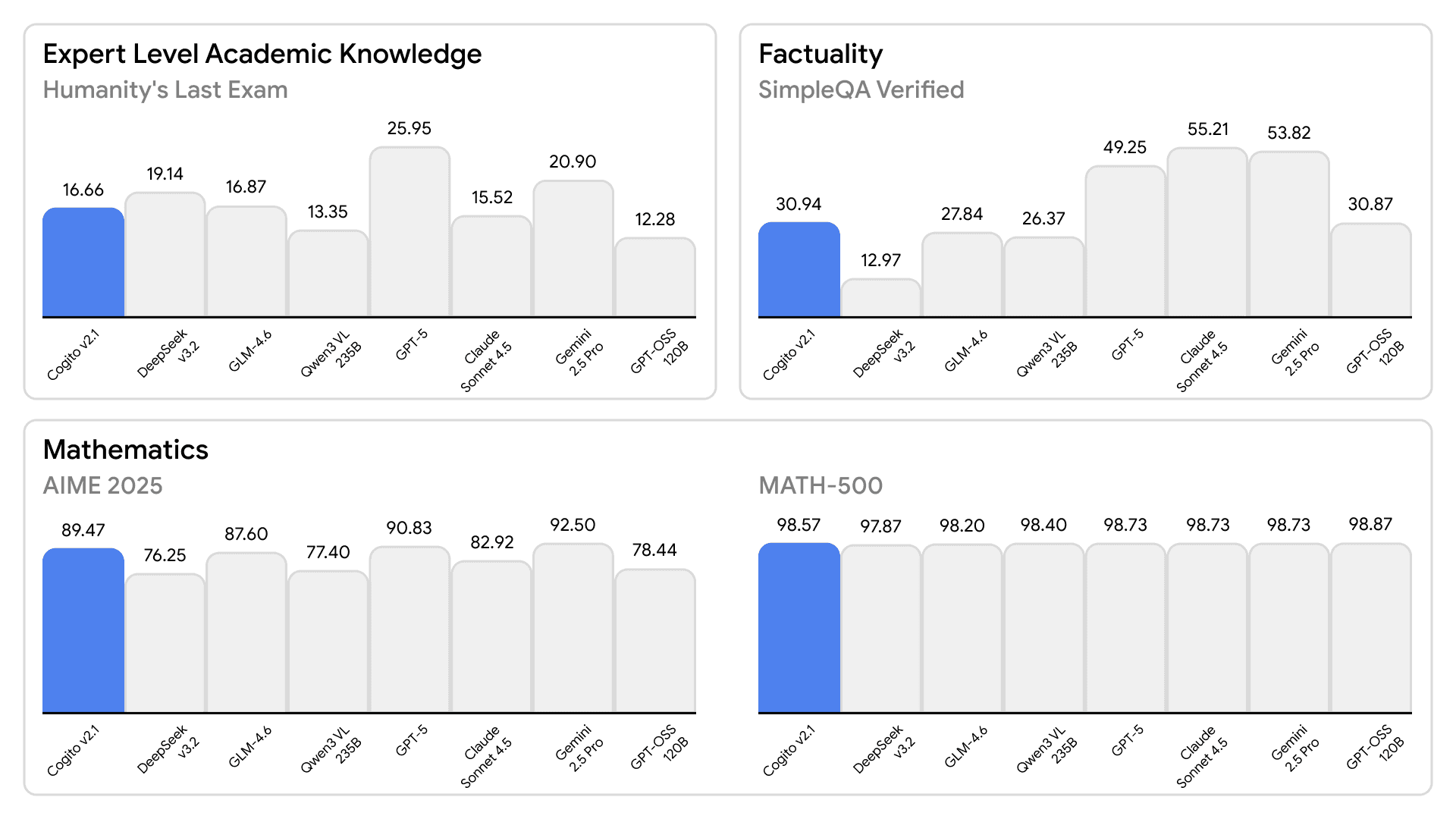
We have added evaluations on a few standard benchmarks.
(Note - while these benchmarks provide a useful signal, they do not fully capture real-world performance. That said, our models have been tested across multiple internal and external evaluations and consistently perform well.
Ultimately, the best evals are the ones closest to the user's needs. We encourage users to test out the models on the chat interface directly.
We are confident that our models will stand up to such real-world evaluations and deliver strong results in practice.)
Cogito models are trained via process supervision for the reasoning chains. As a result, the model develops a stronger intuition for the right search trajectory during the reasoning process, and does not need long reasoning chains to arrive at the correct answer.
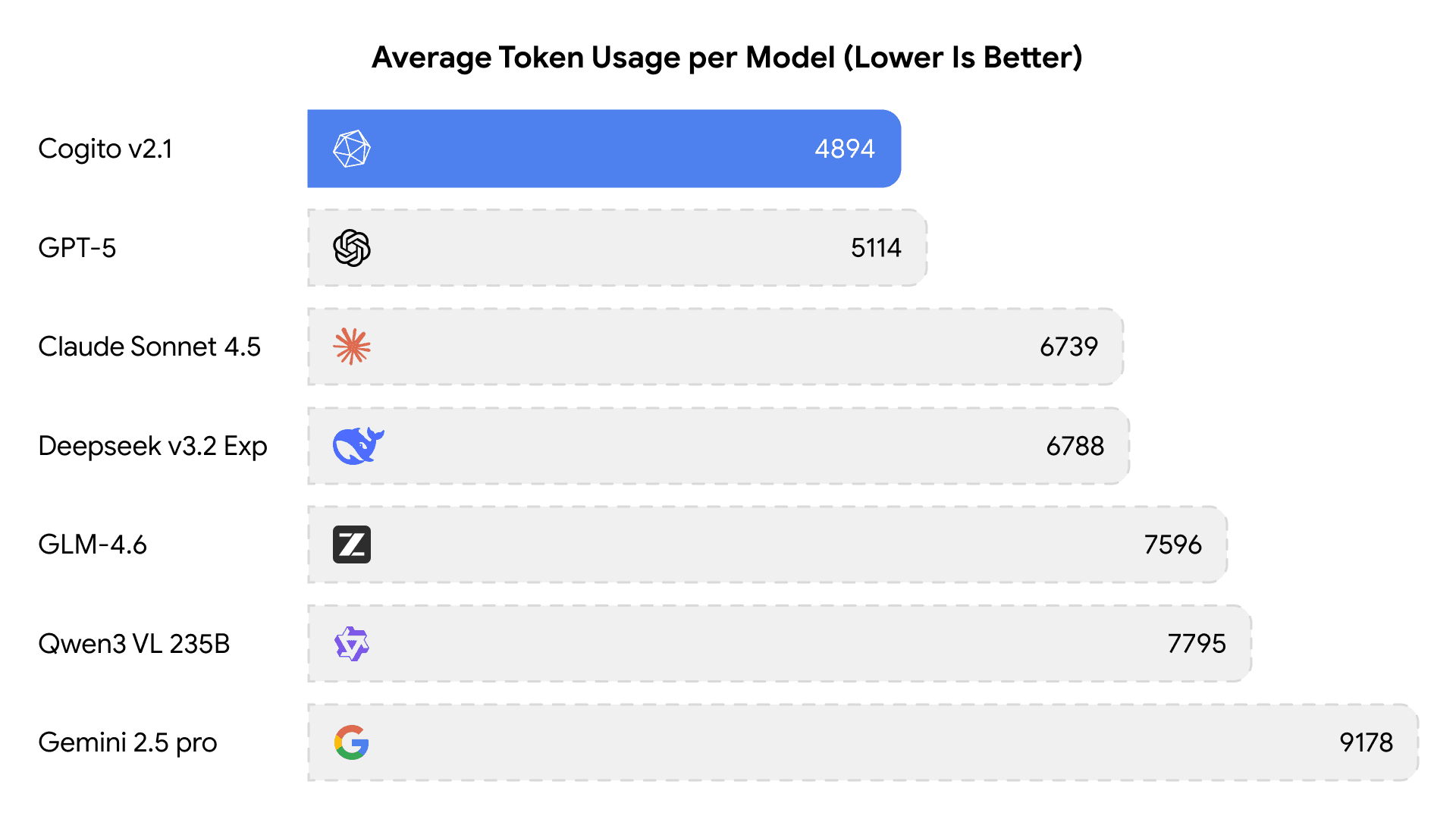
Cogito v2.1 model has the lowest average tokens3 used with respect to reasoning models of similar capabilities.
1 Similar to Cogito v2, we fork off the open-licensed Deepseek base model from November 2024 and run post-training in-house for Cogito v2.1.
2 For SWE-Bench, we used the Agentless framework as orchestration to perform code repair localization in each instance's repo and patch generation OpenAI's text-embedding-3-small model was used during the RAG step. The presented numbers is Single Patch without Test (accuracy), with max output tokens for each model call set to 16384 (except for Qwen3-VL 235B, which was set to 32768, due to otherwise unusable evaluation comparison due to frequent response length violation).
Metric types: 'accuracy' for non-coding benchmarks (AIME, GPQA Diamond, MATH-500, MMLU-Pro, HLE, MMMLU), 'f1' for SimpleQA Verified
Repeats per example: AIME (32), GPQA Diamond (8), MATH-500 (3), MMLU-Pro (1), HLE (1), SimpleQA Verified (1), MMMLU (1)
3 The graph shows the average tokens used per benchmark instance, averaged over all benchmarks.

